IBM i and Continuous Integeration
What is Continuous Integration ?
I won't go into details here what Continuous Integration (CI) is because there are many people who can do that better than me. So here is the Wikipedia article about CI.
Why CI even if you are a single developer in your shop?
Having a build server can be handy for many reasons:
- Build server can be setup to have the same environment as the production environment. The development environment often differs from the production environment.
- Every build is done in exactly the same way.
- Builds can be triggered regardless of the developer machine.
- Release builds
- … and there are many many more
Here some quotes from the net:
The CI build can also be thought of as your “release” build. The environment should be stable, and unaffected by whatever development gizmo you just add to your machine. It should allow you to always reproduce a build. This can be valuable if you add a new dependency to your project, and forget to setup the release build environment to take that into account. Is Continuous Integration important for a solo developer?
Likewise, if you are building libs that are used by multiple projects then CI will make sure they work with ALL of the projects rather than just the one that you're working with right now… Is Continuous Integration important for a solo developer?
Build Server
Jenkins is used as a build and CI server. It supports master and slave nodes.
If Jenkins is run on the system where all the builds should be executed it can be run as a master which is also the default.
If Jenkins is run on another platform and builds should be executed on an IBM i server Jenkins can be normally run as master node and slaves nodes need to be configured so that builds can be delegated to slave nodes.
Installation
Jenkins can be downloaded here.
The installation is pretty straight forward. Jenkins is packaged as a war file but also supports executing the file as a normal Java application. It needs at least a Java Runtime Environment 1.7. You can check this with
java -jar version
It should output something like this:
java version "1.7.0_121" OpenJDK Runtime Environment (IcedTea 2.6.8) (7u121-2.6.8-2~deb7u1) OpenJDK 64-Bit Server VM (build 24.121-b00, mixed mode)
Jenkins can be started with
java -jar jenkins.war
The Jenkins project has an extensive documentation. The wiki provides a page Installing Jenkins. A list of parameter (f. e. http port) can also be found in the project wiki.
All the data will be stored in the .jenkins folder in the home directory of the user.
Jenkins and Screen
screen is a handy tool on linux systems to run programs interactively but in the background.
screen -dmS jenkins bash -c "java -jar /opt/jenkins.war"
To detach from a screen session enter CTRL-A + D.
screen -list lists all running screen sessions.
To attach to a running screen session enter
screen -r jenkins
Configuration
In most cases the build server runs on a dedicated machine (either real or virtual). To execute compiles on architectures other than the one where the build server is running the concept of master and slave nodes needs to be installed.
The normal installation is always acting like a master node.
See Distributed builds in the Jenkins wiki.
To communicate with the slave node system the SSH Jenkins plugin needs to be installed, see Main Page ⇒ Manage Jenkins ⇒ Manage Plugins.
Slave Node
We need to configure a slave node for the IBM i server so that we can compile and test ILE code, like RPG and CL.
Slave nodes can be configured in Jenkins in the Main Menu ⇒ Manage Jenkins ⇒ Manage Nodes ⇒ New Node , select “Permanent Agent”.
As there need to be some files and programs on the slave node to execute the build job we need to create a directory in the IFS, f. e. /usr/local/jenkins or /var/local/ci. Enter this directory in the “Remote root directory” in the node configuration.
Set “Launch method” to “Launch slave agents via SSH”. Configure “Host” and “Credentials”.
Set the labels to use in the job configuration, f. e. ibmi. Labels determine on which node the build will be executed.
Job
A Build Job defines what is build where and when. It defines the build environment.
Build Jobs can be configured in Jenkins in the Main Menu ⇒ New Item. Configure the job as a “Freestyle Project”.
The label determines where the job is run. This can be set on the “General” tab, “Restrict where this project can be run”. Enter the label you specified on the IBM i slave node or enter the name of the slave node itself if it should run specifically on this node.
Build Steps
git clone git@bitbucket.org:m1hael/linkedlist.git $WORKSPACE cd $WORKSPACE $WORKSPACE/setup
The source code is fetched from a git repository and the compile commands are in the setup script.
$WORKSPACE is a variable set by Jenkins and points to the directory of the job.
To make the setup script more flexible you can specify the target library via an environment variable. Install the EnvInject plugin for that and configure TARGET_LIB=MYLIB in Properties Content in the Build Environment tab of the job.

Example Setup Script
#!/QOpenSys/usr/bin/sh
export PWD=$(pwd)
if [ -e /qsys.lib/$TARGET_LIB.lib/llist.file ] ; then
system -kpieb "DLTOBJ OBJ($TARGET_LIB/LLIST) OBJTYPE(*FILE)"
fi
system -kpieb "CRTSRCPF FILE($TARGET_LIB/LLIST) RCDLEN(112)"
system -kpieb "CPYFRMSTMF FROMSTMF('$PWD/llist.bnd') TOMBR('/QSYS.LIB/$TARGET_LIB.LIB/LLIST.FILE/LLIST.MBR') MBROPT(*REPLACE)"
if [ -e /qsys.lib/$TARGET_LIB.lib/llist.module ] ; then
system -kpieb "DLTOBJ OBJ($TARGET_LIB/LLIST) OBJTYPE(*MODULE)"
fi
if [ -e /qsys.lib/$TARGET_LIB.lib/llist_sort.module ] ; then
system -kpieb "DLTOBJ OBJ($TARGET_LIB/LLIST_SORT) OBJTYPE(*MODULE)"
fi
system -kpieb "CRTRPGMOD $TARGET_LIB/LLIST SRCSTMF('llist.rpgle') OPTION(*SRCSTMT) DBGVIEW(*LIST) OPTIMIZE(*BASIC) STGMDL(*INHERIT)"
system -kpieb "CRTRPGMOD $TARGET_LIB/LLIST_SORT SRCSTMF('llist_sort.rpgle') OPTION(*SRCSTMT) DBGVIEW(*LIST) OPTIMIZE(*BASIC) STGMDL(*INHERIT)"
if [ -e /qsys.lib/$TARGET_LIB.lib/llist.srvpgm ] ; then
system -kpieb "DLTOBJ OBJ($TARGET_LIB/LLIST) OBJTYPE(*SRVPGM)"
fi
system -kpieb "CRTSRVPGM $TARGET_LIB/LLIST MODULE($TARGET_LIB/LLIST $TARGET_LIB/LLIST_SORT) STGMDL(*INHERIT) EXPORT(*SRCFILE) SRCFILE($TARGET_LIB/LLIST) TEXT('Linked List')"
# cleanup
system -kpieb "DLTOBJ OBJ($TARGET_LIB/LLIST) OBJTYPE(*FILE)"
system -kpieb "DLTOBJ OBJ($TARGET_LIB/LLIST) OBJTYPE(*MODULE)"
system -kpieb "DLTOBJ OBJ($TARGET_LIB/LLIST_SORT) OBJTYPE(*MODULE)"
if [ ! -e /qsys.lib/$TARGET_LIB.lib/llist.srvpgm ] ; then
exit 1
fi
Tagging Build Objects
To identify from which source code revision the objects has been build we need to tag the objects with an identifier. The identifier could be the source code revision which can be retrieved from a git repository with the following line
git show -s --format=%h
Output: 14b44a3
To make sure that we only get the first 7 characters regardless of the output of the git command we can pipe the output to the head command like this
git show -s --format=%h | head -c 7
QSYS objects can only store user information in two attributes:
- object description
- user-defined attribute
We will use the user-defined attribute though it can only hold 10 characters of information.
The program UPDUSRATTR available through the OSSILE project can put this information on the object. We need to pass the following information as parameters:
- library name of the object
- object name
- object type (f. e. *PGM)
- tag / user defined information (max. 10 characters)
CALL UPDUSRATTR PARM('MSCHMIDT1' 'LLIST' '*SRVPGM' 'GIT14b44a3')
In the setup script it may look like this:
GIT_COMMIT_HASH=GIT$(git show -s --format=%h | head -c 7)
system -kpieb "CALL MSCHMIDT1/CIUPDOBJD PARM('$TARGET_LIB' 'LLIST' '*SRVPGM' '$GIT_COMMIT_HASH')"
Unit Testing
I used ILEUnit for unit testing builds. There is also the RPGUnit framework but that doesn't support test report output to stream files.
The unit tests are service programs which must be build like the rest. There is a setup script which builds the unit test service programs.
cd $WORKSPACE/unittest $WORKSPACE/unittest/setup
The execution of the unit test is also covered in the setup script.
system -kpieb "IURUNXML IFS('$WORKSPACE/unittest/llist_ut_1.xml') TSTLIB($TARGET_LIB) TSTPGM(LLIST_UT_1)"
if [ ! -e $WORKSPACE/unittest/llist_ut_1.xml ] ; then
exit 1
fi
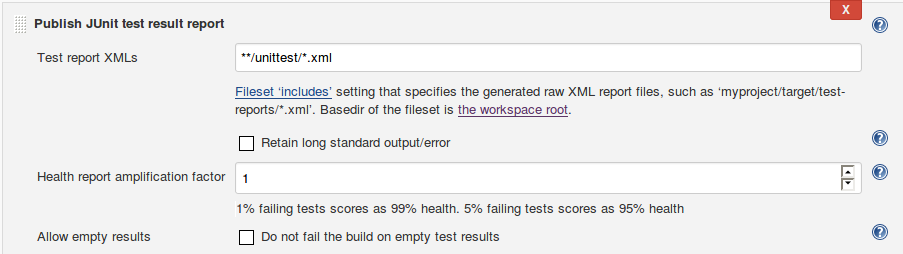
Create Unit Test Report
In the previous step we run the unit test and create the xml stream files in the unittest folder in our Jenkins job directory. The files are automatically transferred from the slave to the master node.
Now we need to say Jenkins where to find the files.
Open Tasks
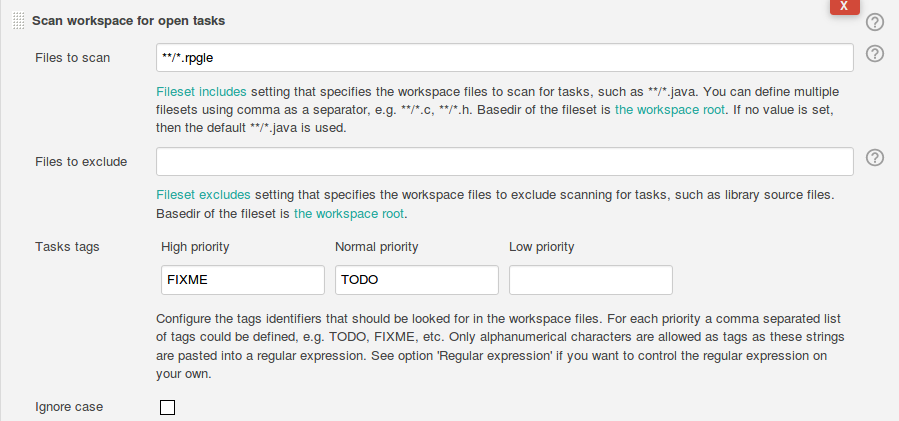
Jenkins provides a rich set of plugins. One of those plugins is the Task Scanner Plugin. It is very flexible in identifying open tasks by keywords like TODO or FIX ME. The good thing is that it is also executed on the slave node so we can use it to scan the source code on the IBM i server.
First we need to configure the keywords and the files to be scanned (in this case TODO and FIX ME as keywords and all files with the suffix rpgle).
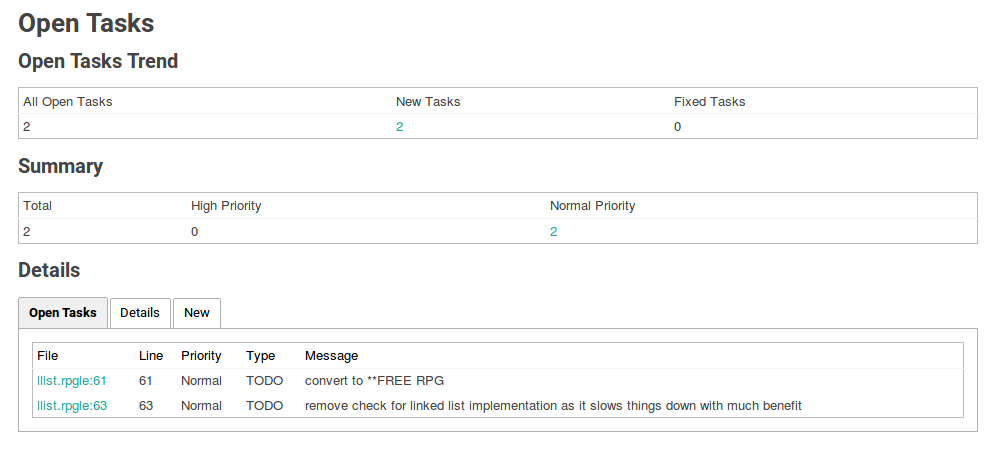
The result of the scan looks like this:
Lint
In almost any programming languages exists a lint module which does some generic code checking. Of course there is no such thing for RPG but one could do some checking with a simple text search using regex.
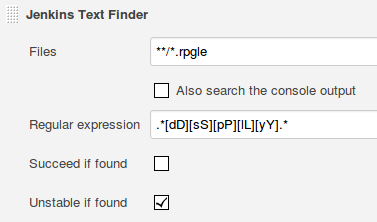
An example would be if there shouldn't be any DSPLY command in the source code (left over from some testing or debugging session). So you could use the following regex to identify such lines:
.*[dD][sS][pP][lL][yY].*
There is the Text Finder plugin which can be configured with any regex and the option to mark the build UNSTABLE if such a line is found.
Ideas
- building documenation (ILEDocs)
- making save file from compiled objects
- ftp save file to archive